quiethumans: a search engine for the makers the internet forgot
It crawls personal websites, judges them with a tiny model on my own hardware, and hands the final curation to a Claude client over MCP. The heavy AI costs nothing per call; running it myself is where I kept hitting walls.
The web rewards the loud. Search a name and you get whoever optimised hardest for being found: the people with the most followers, the busiest feeds, the cleanest "top 100" lists. The person quietly building the most interesting thing on a hand-coded site with a /now page rarely surfaces at all.
quiethumans is my attempt at the opposite. It crawls personal websites, works out what each person actually makes, and lets you search for people by the thing they build rather than their job title. Not "react developer, 5 years experience" but "makes generative art from git commits." It runs the AI on my own hardware, so it costs nothing per call, and it does the part everyone hand-waves over - deciding who is interesting - by handing that one judgment to a stronger model over MCP. This is how it is built, and the wall I hit running the models myself.
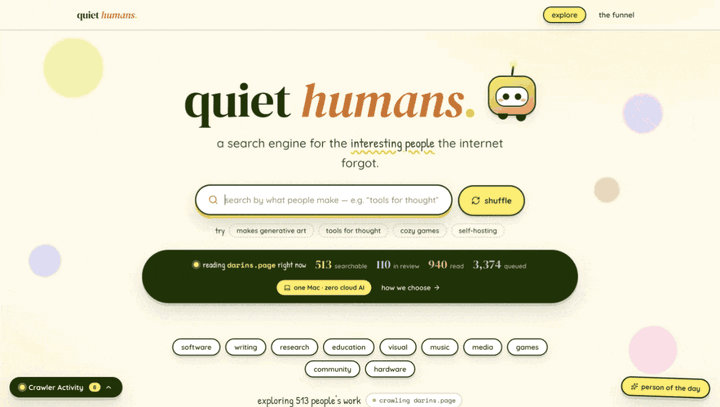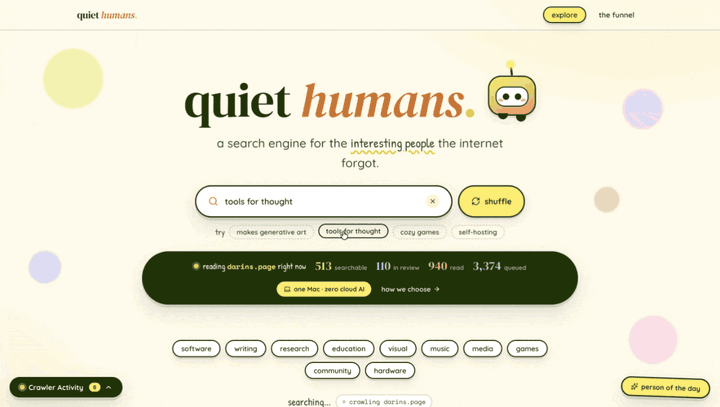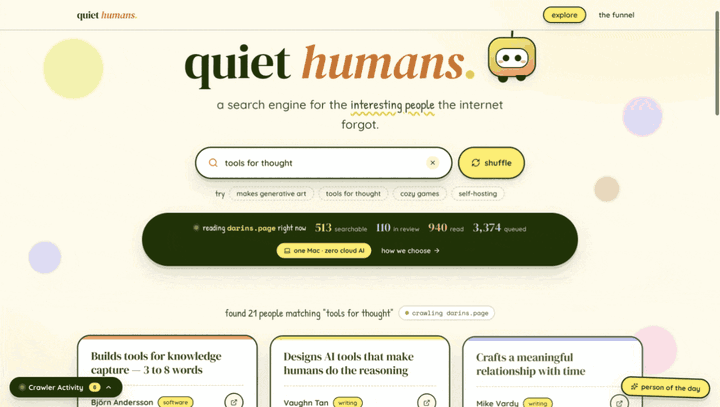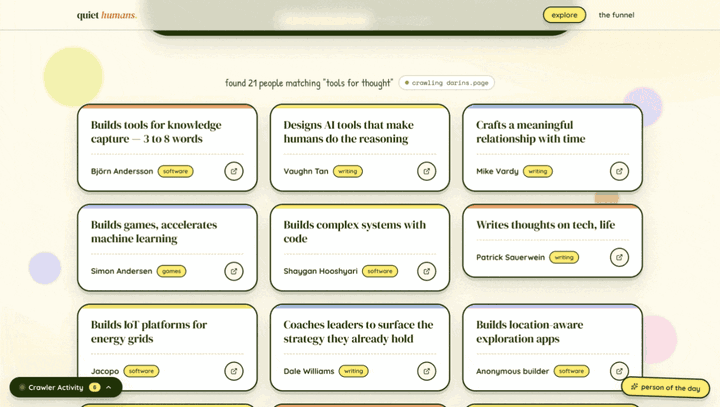
Search by meaning, not keywords
What I wanted to build was simple to describe: type an idea, get the people who live it. In the clip above I searched "tools for thought" and the top results were "builds tools for knowledge capture" and "designs AI tools that make humans do the reasoning." Zero of those share a word with the query. They matched because the search understood the idea and found the people closest to it.
That works because every approved person, and each individual thing they have made, is turned into a 768-number fingerprint that captures meaning rather than wording. Searching is just embedding your query the same way and asking which fingerprints sit nearest. A self-hosted EmbeddingGemma makes the fingerprints; a self-hosted Qdrant stores them and answers "who is near this point." When nothing is close enough, it falls back to plain keyword search so the page is never empty.
A pipeline that spends nothing until it has to
Behind the search box is an assembly line. The ordering is the whole trick: the free and cheap steps run first, and the one expensive judgment runs last, on the handful of candidates that survive. Click a stage to see what it does and where the cost lands.
The first three stages never touch a model. Discovery pulls candidate URLs from ten places where indie builders gather - personal-site directories like nownownow and ooh.directory, the IndieWeb webring, Neocities, Hacker News, Reddit, and GitHub "awesome" lists - and drops them in a Postgres queue. Filtering then bins the obvious nos with plain rules: company domains, shops, docs sites, platform subdomains, anything too thin to be a person. Only the maybes cost anything. By the time the model is involved, most of the web is already gone, for free.
The filter that decides who is a maker
Two judgments are genuinely hard, and they are where the model earns its keep. The first: is this even one person's site, rather than a startup's landing page? The second, once a real person is found: which of their things count as a creation?
That second test runs in two steps, because splitting it makes a tiny model reliable:
- Is it a real creation? A tangible thing they made and shipped - an app, tool, library, game, piece of hardware, a published book or album, research, a course. Not an opinion post, a review, a how-to, a life update, or a repost. This binary call is steady even on a small model.
- Does it have a spark? Kept if it is novel, playful, technically crafted, or a clever fix for the person's own problem, even if it is useless to anyone else. Dropped if it is generic: a plain blog, bare config, a by-the-numbers tutorial exercise, or mostly an employer's team work.
The thresholds in that filter were not guessed. I tuned them by comparing the small model's calls against a set I had labelled by hand, until its keep/drop decisions tracked what a stronger model would have said. The gate at the end is blunt on purpose: a person needs to have shipped something real to get in. Talkers without proof never clear it.
The decision I am most happy with: curation lives outside the pipeline
Here is the part I would do the same way again. The crawler makes no keep/reject decision. Every person it processes is saved as pending_review and nothing more. The pipeline's job is to extract facts - name, projects, interests, what they make - not to pass judgment on whether they are interesting.
Judgment happens afterwards, in a separate step, performed by a stronger reviewer: either me through a small review UI, or a Claude client connected over a token-gated MCP server. Approving a person is the moment they become public - only then are they and their creations embedded and added to the search index. Rejecting throws the staged data away.
Splitting it this way buys two things. The cheap self-hosted model runs flat out on the boring, high-volume work. The expensive judgment - the call that actually shapes what the site feels like - is made by something better, on the small pile that is left, without being wired into the crawl loop where it would slow everything down.
There is one more thing the reviewer does, and it is the only place a cloud model touches this project at all. The local model is good at facts but writes stiff, hedge-everything prose. "Software developer who works on various web projects and tools" is technically true and tells you nothing. So a Claude client reads the extracted facts and rewrites just the human-facing lines. Flip the writer:
The safety rail is in the data layer, not in good intentions. The MCP update_profile tool can write to exactly five fields - hook, one_liner, work_summary, current_focus, unique_angle - and the database rejects any attempt to touch anything else. Claude rewrites the words; it can never edit the facts underneath them. The whole MCP surface is five small tools:
| MCP tool | What the reviewer can do |
|---|---|
search_profiles |
List people, usually the ones still pending_review |
get_profile |
Read one complete profile |
update_profile |
Rewrite text - and only the five whitelisted fields |
approve_profile |
Approve with a 1-10 score; embed and index the person |
reject_profile |
Reject and pull them from the index |
The server speaks SSE, sits behind Caddy for TLS, checks a bearer token on every request, and stays switched off entirely unless an MCP_TOKEN is set. DNS-rebinding protection is off in the server itself only because the TLS and auth happen one layer up.
One tiny model, many hats
Almost everything that needs intelligence runs through a single self-hosted model, Gemma in its small "E4B" size, behind an OpenAI-compatible endpoint. It wears five hats: classify a site, score which pages are worth reading, extract the profile, score interestingness at review time, and (as EmbeddingGemma, from the same endpoint) make the search fingerprints. No per-token bill, no rate limits, no data leaving for an API. The lesson that surprised me: a free, tiny model is genuinely good enough to filter, judge, and structure at volume. The cloud only gets the one job where taste matters - the prose - and even that is optional.
What actually runs where
The deck version of this story says "it all runs on one Mac," and in development that was true. The deployed site is split, and the honest version is more useful:
| Piece | Where it runs |
|---|---|
| Web app, crawler, TLS proxy | Three Docker containers (web, pipeline, caddy) on one small DigitalOcean droplet |
| Gemma + EmbeddingGemma | Self-hosted on my own hardware, reached over an OpenAI-compatible endpoint |
| Postgres (the facts) + Qdrant (the fingerprints) | Separate hosted stores, not on the droplet |
So "runs on one machine" is the dev story; "zero cloud AI inference" is the claim that survives into production. The models are mine wherever they live. Deploys are deliberately dumb: push to main, and a script on the droplet pulls, rebuilds the containers, and restarts. No build pipeline, no green-checkmark theatre.
Where local fights back
Running your own models is free and private, and then "local" pushes back. Four walls, in the order I hit them:
- The RAM wall. A chat model and an embedding model both want to stay resident. On a 16 GB machine they do not both fit next to the crawler and the OS, so it kept paging to disk and falling over. The fix was unglamorous: keep concurrency low, one model hot at a time, and trim every prompt hard.
- The context cliff. Gemma advertises a 128K-token context. On 16 GB it pages long before that, so each call is capped near 16K - a long article's worth. The counter-intuitive part: reading the long prompt is the slow step, not writing the answer. The opposite of how cloud APIs bill you.
- Two models, one config fight. Serving an embedding model and a chat model from the same runtime was not a one-line swap. The first embedding model I tried would not load cleanly beside Gemma and returned shapes I did not expect. Settling on EmbeddingGemma, served from the same endpoint with its own task prefixes, is what finally held.
- The leash. One hung site used to stall the whole crawl, until I added a hard per-URL timeout. And a laptop you cannot close the lid on is a poor always-on server. Local is free; it is also a leash. A roughly 12-euro-a-month rented box buys "always on," and that is the trade: free but tethered, or a couple of coffees a month and it never sleeps.
All the thinking cost nothing. Here is the index the morning I wrote this. The numbers move as it crawls - the live versions tick away on the site itself:
What I would tell you
Most of the web is junk, so filter ruthlessly before the model ever sees it. Small local models punch well above their size at classifying, judging, and structuring - all of it ran on hardware I own. But local has a real ceiling: RAM, two-model configs, and a machine you end up babysitting. And the one decision worth protecting - who is interesting - is the one I deliberately kept out of the automated loop, handed to a stronger model over five small MCP tools, with a data layer that lets it fix the words and never the facts.
The code is open: github.com/ankitaggarwal/quiethumans.fyi. The search is live at quiethumans.fyi. Go find some quiet humans.